Building a New MindsDB Integration: A Step-by-Step Guide With Examples From the GitHub Handler
From #WoodstockAI to MindsDB Hackathon

Open Source AI Revolution and MindsDB
"Are you going to the Open Source AI event this Friday?"
"I don't know. What is that?"
"Check out this tweet from @ClementDelangue."
"3,000 people attending?! Joined the waitlist. Open Source AI, count me in!"
My good friend Didier and I had this conversation on March 29th. Two days later, both of us met to attend what was dubbed #woodstockAI, an event that started as a casual meet-up with HuggingFace CEO but turned into one of the largest tech events in San Francisco this year. Over 5,000 people showed up without much planning or promotion just to share the excitement about Open Source AI.

At the event, Joseph Jacks introduced me to Jorge Torres and Ian McIntyre. This was the first time I heard about MindsDB. I heard from Jorge that the project has been accelerating and that they are looking for community help implementing integrations. Ian told me about the SF AI Collective meetup.
The enthusiasm for one of the most complex technologies, AI, the enthusiasm for Open Source, the optimism for the future that I saw at #woodstockAI are a tremendous inspiration. It feels like the beginning of something big. I am not quite sure what it is, but I know I want to be a part of it.
I left with a list of ideas, and one of the top ideas was getting to know MindsDB, cloud.mindsdb.com. The next day, through MindsDB GitHub, I learned about the MindsDB Hackathon on HashNode, hashnode.com.
3 Tips for First-Time MindsDB Contributors
Getting started with writing code for a new project can be overwhelming. Having gone through project onboarding a few times, I can share the following shortcuts that helped me start writing code for MindsDB in less than a day.
1. Leveraging Python Tools
Local development setup is one of the most impactful factors when it comes to developer productivity and delight. GitHub Copilot, VSCode, Pyenv, Anaconda, Black, Ruff, and cSpell are indispensable tools in my arsenal.
GitHub Copilot is an AI agent that suggests the next few lines of code to write. For me, Github Copilot accelerates code development by several orders of magnitude. VSCode with Copilot and ChatGPT turns every coding session into a pair-programming exercise. While GitHub Copilot is not needed for this tutorial, it is one of the tools that deserves the highest praise, especially when it comes to AI and working on open source.
VSCode is a free, open-source, modern Integrated Development Environment (IDE) offering a huge library of extensions, infinite tuning, and customization. For many developers, VSCode is the only code editor they will use for quite some time. Released in 2015, VSCode quickly became the dominant tool in the industry. I spend a significant part of my day in VSCode writing Golang, Python, Jupyter Notebooks, YAMLs, and Markdowns. VSCode has excellent integrations with GitHub, putting powerful revision control and GitHub Actions automation features at your fingertips. VSCode is a great debugging environment for Python, and I discuss debugging as a recommended software development technique in this tutorial.
Python is a huge, diverse, complex and rapidly evolving ecosystem. Conflicting dependencies and different Python version targets are problems frequently encountered when working on multiple projects. Maintaining multiple Python Virtual Environments is an unavoidable necessity. Pyenv is my tool of choice to maintain sanity in the world of different Python projects with different requirements. Pyenv is a non-essential, but convenient tool for Mac, Linux or Windows WSL users.
Many of the Python Artificial Intelligence libraries are built as CPython extensions. Different developers will experience Python AI libraries differently depending on whether they use Windows, Mac, or a Linux machine and depending on the CPU (Intel, M1/M2, or ARM). Anaconda is an open-source Python platform that simplifies dependency management by providing reliable pre-compiled versions of popular Python libraries. I use a combination of Pyenv and Anaconda with the majority of my Python projects. I consider Anaconda an essential tool.
As an AI project, MindsDB works with several Python AI libraries. Python AI libraries oftentimes need to make significant changes to keep up with the latest versions of Python. Because of the complicated dependency management, Python 3.9 is the strongly recommended Python version to use with MindsDB. I set up Python for MindsDB in the following way:
$ pyenv install miniconda3-latest
$ pyenv virtualenv miniconda3-latest mindsdb
$ pyenv activate mindsdb
$ pyenv install python=3.9
Black and Ruff are two productivity tools I use with every Python project. Black is an auto-formatter for Python that saves countless hours of typing and arguing about code style. As a bonus, Black serves as an extra syntax check. If Black cannot format a block of code, there is almost certainly an issue. Ruff is a relatively new, amazingly fast Python linter that gives useful, real-time feedback. Ruff and Black greatly simplify Python development. Both Ruff and Black integrate seamlessly with VSCode.
Finally, cSpell is a spellchecker for code. Misspelled words make code confusing. A spellchecker will also help catch cases where the wrong variable is used or introduced unintentionally. I use cSpell as a VSCode extension.
2. Quickly Getting up-to Speed with MindsDB
With Python tools in place, it is time to get MindsDB running locally in the configuration most convenient for development. MindsDB has great documentation and guides. I will highlight two articles that I used in my accelerated setup.
Self-hosted MindsDB is the most convenient configuration for development. After a Python virtual environment is set up, MindsDB dependencies install without much trouble with PIP and requirements.txt. MindsDB makes a smart decision to omit optional dependencies, writes a log of what should be installed to enable a specific integration, and lets the user choose.
From the configured environment, we can launch MindsDB and marvel at the UI that comes up in the browser:
$ python -m mindsdb
At this point, the development environment is all ready, and we can start and stop a local instance of MindsDB (this is a good time to address any issues encountered while launching MindsDB).
MindsDB integration handlers are small, independent components with a broad range of functionality. Integration handlers are perfect parts of the MindsDB codebase for new contributors to work on.
MindsDB contributors have already implemented 97 integration handlers. Picking an integration handler to start studying can be tricky. MindsDB recommends studying the Binance handler and Twitter handler. I recommend starting with the Sheets handler. The Sheets handler is one of the simplest handlers that does not require any authentication keys. The Sheets handler has all the information to get started in the MANUAL_QA document.
In our local MindsDB UI, we run the following SQL command:
CREATE DATABASE job_placement_datasource
WITH ENGINE = 'sheets',
PARAMETERS = {
"spreadsheet_id": "1YNC_dsngcJtpY_SGjCBvOujAocWhDbvlRfFshkPLOh8",
"sheet_name": "Job_Placement_Data"
};
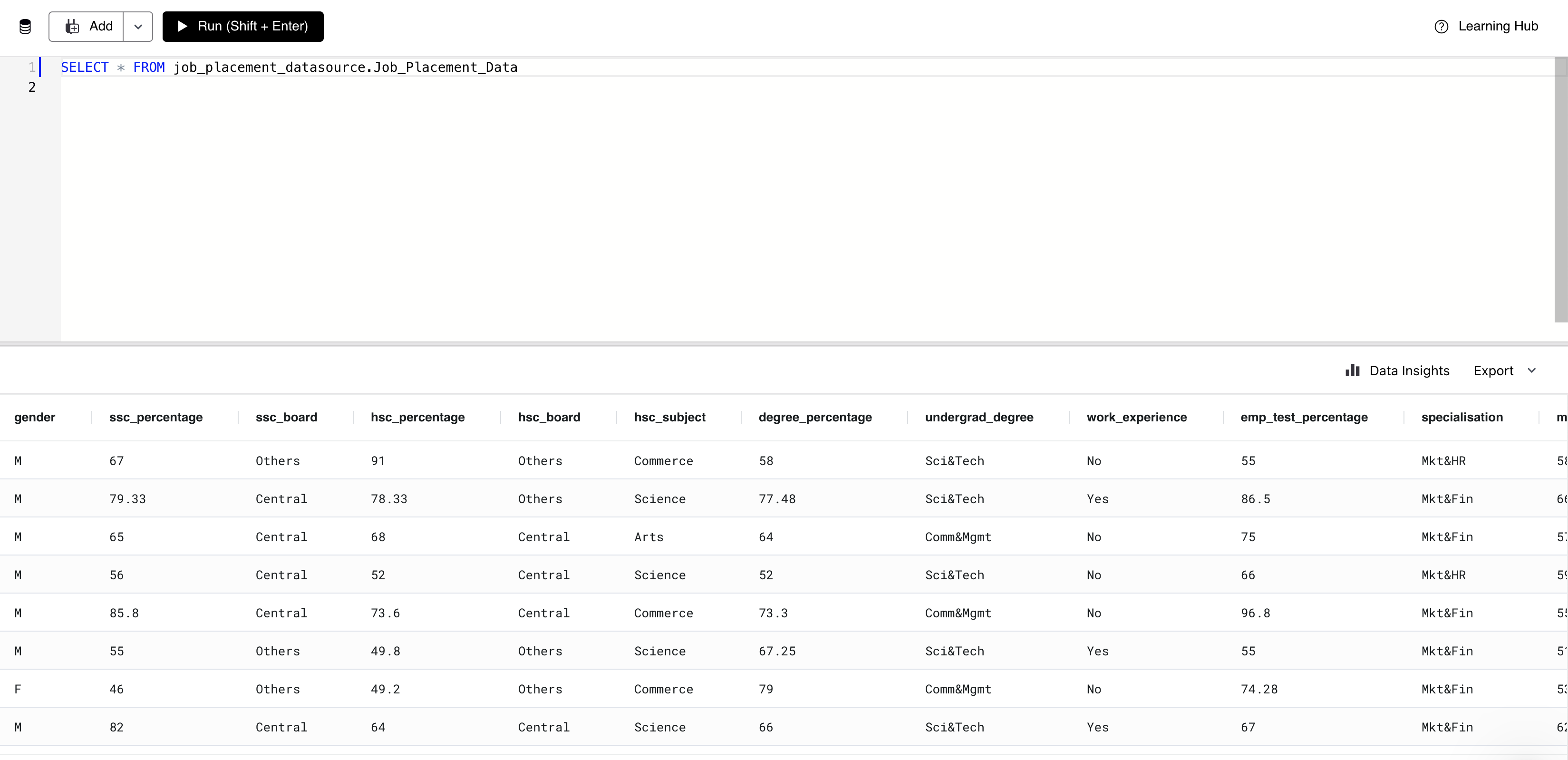
Now we can start following the Sheets handler code to better understand how MindsDB handlers work. We can show the Google Sheet data using a select query:
SELECT * FROM job_placement_datasource.Job_Placement_Data
3. Debugging and Prototyping
The ability to quickly execute specific code blocks within large codebases, like MindsDB, is one of the most important skills in software development. Two common approaches to the quick execution of specific code blocks are Unit Tests and Debugging. Comprehensive Unit Test suites require significant and continuous investments from codebase owners. MindsDB started implementing Unit Tests, but the suite is not yet at the point of broad usability. We are left with Debugging techniques as a way to quickly execute specific code blocks.
Stepping through code in a debugger is one of the best ways to get familiar with implementations. To use the Sheets handler as an example, let's walk through the sheets_handler.py file in a debugger. In VSCode, we can launch the debugger through the "Run and Debug" menu. For MindsDB, we will launch a debugger on the mindsdb module. We can set a breakpoint on the first line inside the connect method and run the SELECT * FROM job_placement_datasource.Job_Placement_Data query again. VSCode will stop execution at our breakpoint, and we can look into how the rest of the code in the connect method is executed.
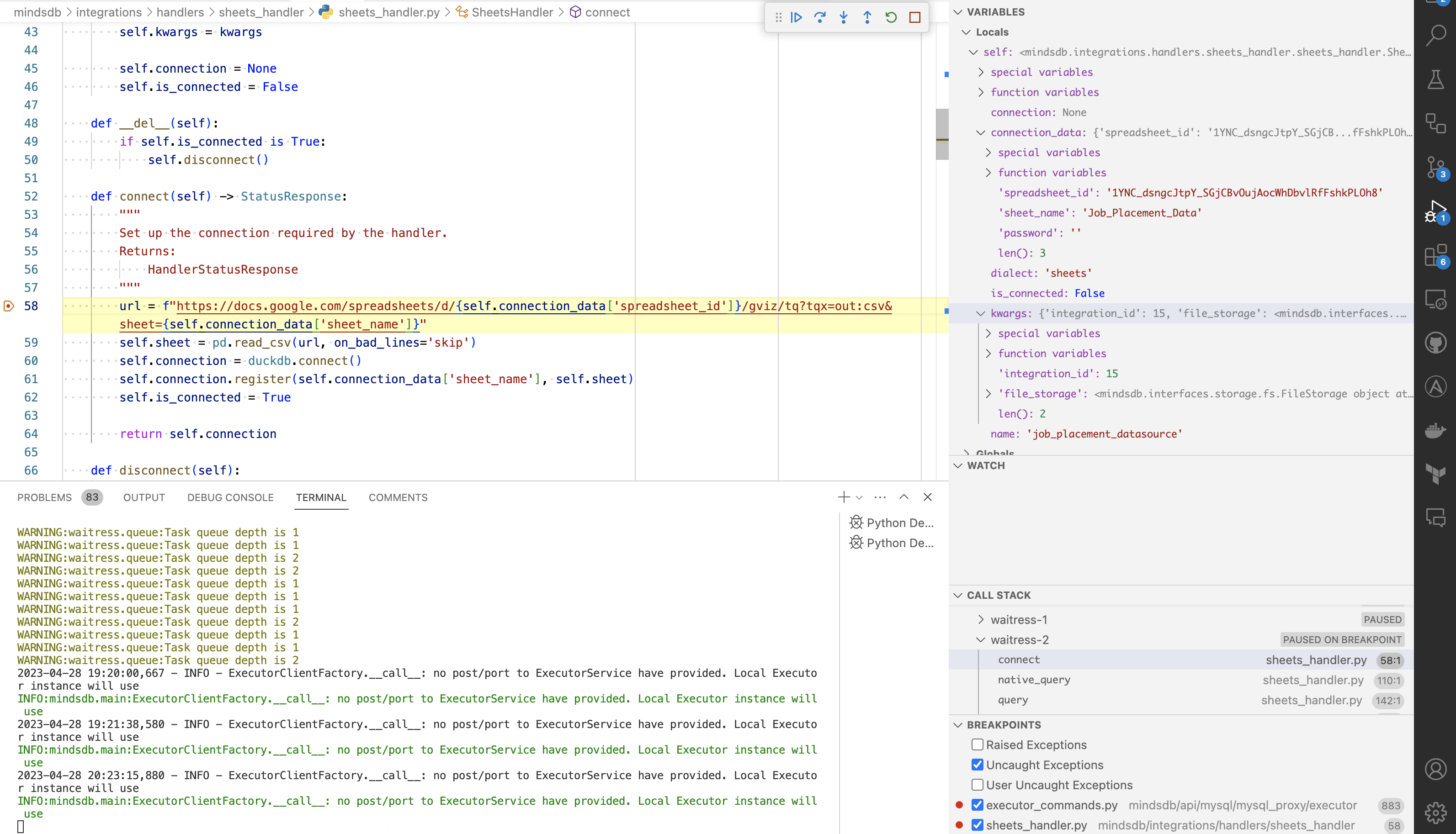
I learned to code before any major Unit Testing frameworks were developed. Code Debugging skills remain one of my go-to techniques, although I now use Unit Testing more often. Unit Testing and Debugging can be used in conjunction to even greater effect. Debugging the Sheets handler will allow a new contributor to come up to speed on how MindsDB integration handlers work very quickly.
Prototyping is the last technique I want to highlight for first-time contributors. Developing a quick, stand-alone prototype of key integration functionality before putting new code into MindsDB handler framing oftentimes leads to faster implementation. In the next sections, I will show simple prototypes that helped me accelerate the development of the GitHub handler.
Checkpoint 1:
So far we have the following:
A Python 3.9 virtual environment with MindsDB dependencies
A local MindsDB instance with a Sheets handler example
A working debugger
A foundational understanding of how MindsDB handlers work
Designing a MindsDB Integration
The first step in designing a MindsDB integration is selecting an application to integrate with. The options for MindsDB API integration handlers are limitless. Practically all service APIs are candidates for MindsDB handlers. For the MindsDB Hackathon, the MindsDB team created the following list of app integration suggestions. Picking the GitHub Integration issue was an obvious choice for me. I have used GitHub APIs for over a decade, and I consider GitHub APIs to be one of the best interfaces available.
The next two steps of the design are creating a Logical Data Model and finding a Python library that implements selected APIs.
To create a Logical Data Model, we want to study selected APIs and decide what API objects will become MindsDB databases, what objects will become MindsDB tables, and what objects will become rows of MindsDB tables.
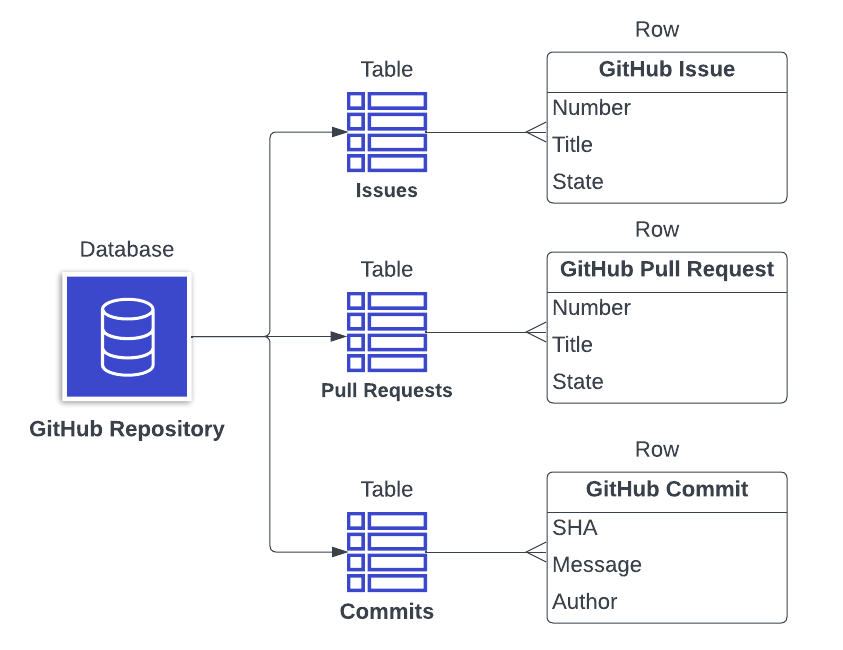
For the GitHub handler, I revisited the GitHub API documentation. Deciding on a Logical Data Model can be one of the most difficult steps in creating a MindsDB integration. My prior experience working with GitHub APIs helped me immensely to quickly create the following Logic Data Model. The GitHub Repository is the most interesting GitHub object. The GitHub Repository contains Issues, Pull Requests, Collaborators, Commits, and other interesting objects. I decided to map GitHub Repositories into MindsDB databases and map Issues, Pull Requests, Collaborators, and Commits into MindsDB tables. Specific issues, pull requests, commits, etc will become MindsDB rows in their respective tables.
Python libraries exist for just about any service API available. Finding a Python library for the GitHub APIs was trivial. Pygithub is the library that I used for quite some time with great success.
The last step of the design is to create an implementation plan and start writing the MindsDB handler's README. I followed the examples in existing handlers to create a README for the GitHub handler.
Checkpoint 2:
We progressed our MindsDB handler development efforts by adding the following:
An API source for a MindsDB handler
A Python library that implements the API source
A Logical Data Model that maps the API source into MindsDB databases/tables
A high-level implementation plan
Implementing a New Integration
The first step of the implementation is creating a quick prototype. For a MindsDB handler, a quick prototype can be as simple as importing the Python library selected during the design, authenticating with the chosen API, and running basic API queries. For the GitHub handler, my prototype looked like the following:
import os
import github
args = {}
args["login_or_token"] = os.environ['GH_TOKEN']
gh_handle = github.Github(**args)
print(f"Current user: {gh_handle.get_user().name}\n")
for an_issue in gh_handle.get_repo("mindsdb/mindsdb").get_issues(
state="all",
direction="asc",
)[:10]:
print(f"{an_issue=}")
Figuring out API authentication intricacies may take a few iterations. The next step after getting a working prototype is to create a MindsDB handler file layout.
mindsdb/integrations/handlers
├── ${api_name}_handler
│ ├── README.md
│ ├── __about__.py
│ ├── __init__.py
│ ├── ${api_name}_handler.py
│ ├── ${api_name}_tables.py
│ ├── icon.svg
│ └── requirements.txt
The README.md is the MindsDB handler README started during the design. The __about__.py is a file that contains the metadata of the new handler. The __init__.py the Python module initialization logic for the new handler. The icon.svg is an API logo to be displayed in the MindsDB UI. The requirements.txt is a PIP file that will install the Python library we identified during the design. ${api_name}_handler.py and an optional ${api_name}_tables.py will contain the implementation of the new MindsDB handler.
With the MindsDB handler file structure in place, work on the Python logic of the MindsDB handler starts. ${api_name}_handler.py will contain the Python class for the new MindsDB handler. __init__, check_connection, connect, and native_query are the four methods of the Python MindsDB handler class to start writing.

The NewAPIHandler.__init__ method parses MindsDB handler inputs such as authentication credentials and hierarchy references coming from the CREATE DATABASE SQL statement used to create a class instance. For the GitHub handler, the MindsDB database instance is initialized with one required parameter, the repository name, and several optional parameters.
The prototype created at the beginning of this section should have enough code for the NewAPIHandler.__init__ and NewAPIHandler.connect methods. After implementing the NewAPIHandler.__init__ method, I recommend using the Debugging techniques discussed in the "3 Tips" section of this article to see the init method in action. The GitHub handler initialization can be started with the following CREATE DATABASE command in the MindsDB UI:
CREATE DATABASE mindsdb_github
WITH ENGINE = 'github',
PARAMETERS = {
"repository": "mindsdb/mindsdb",
};
The next step after the NewApiHandler class is to start implementing MindsDB tables holding the data coming from the APIs. The ${api_name}_tables.py file will have the NewApiNewTable Python class, and new tables will be registered and initialized in the NewAPIHandler.__init__ method of the NewApiHandler class. A NewApiNewTable Python class will have the following core structure:

The algorithm with which the API data is mapped into MindsDB tables is the most interesting part of the new MindsDB handler implementation. MindsDB tables receive input from SQL statements such as SELECT, INSERT INTO, UPDATE, and DELETE. SQL statements and SQL statement parameters are mapped into API features. A sequence of API calls is added to the algorithm, and the data returned by the API calls is aggregated into a Pandas data frame. The final data frame is returned as a response to the SQL call.
I started the GithubIssuesTable implementation by writing the SELECT SQL query logic. SQL SELECT is typically the most frequently executed SQL query with a complex set of parameters. A comprehensive implementation of SQL SELECT can take some time. I focused on implementing the following basic SELECT features:
Columns selected
Rows selected with the
WHEREfilterOrder of rows requested with
ORDER BYThe number of rows requested with the
LIMITclause
I looked for a GitHub API call that would return a list of issues for a given repository and found github.repository.get_issues. I wrote the logic to process SQL SELECT parameters and create arguments for the github.repository.get_issues API call based on the SELECT parameters.

Next, I wrote the INSERT INTO SQL query logic for the GithubIssuesTable. SQL INSERT INTO is a simpler query. I was glad that I decided to re-read the documentation because I forgot that INSERT INTO may be inserting multiple values. I found the github.repository.create_issue call in PyGithub, quickly tried using the call in my prototype, and implemented the insert method.

After finishing the select and insert methods, I tested them in the MindsDB UI with different SQL parameters. I used Debugging to quickly find and address issues in my code.
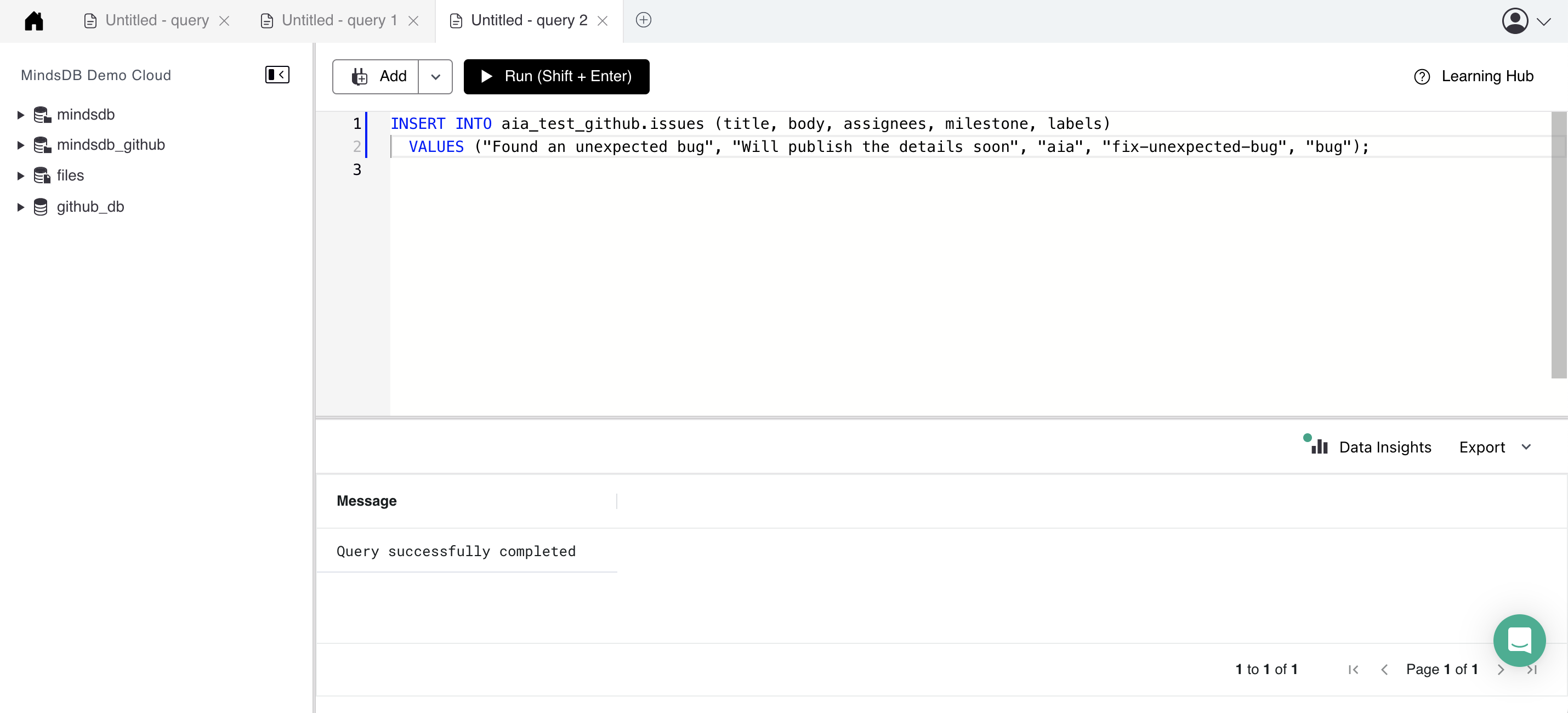
Checkpoint 3:
At this stage in the new MindsDB handler implementation, we should have the following:
A working NewApiHandler class
At least one working NewApiNewTable class
At least a SQL
SELECTmethod is implemented for the NewApiNewTable
First Release of the New Integration
The first release, just like the first impression, can set a long-lasting tone. The MindsDB Contributor's Guide, MindsDB Code of Conduct, and MindsDB Individual Contributor License Agreement are extremely important documents that should be carefully read.
What scope to assign to the first release is an important decision. The first pull request for a new functionality should clearly demonstrate the value of the new functionality. At the same time, the first pull request should be simple enough to review. New functionality increases the scope of the project naturally increasing the complexity of the review. When the implementation of a new functionality does not adhere to common coding standards, does not follow the project's established practices, is convoluted, or is too long, the contribution becomes too difficult for reviewers to support. Python tools recommended in the tips section (Black, Ruff, cSpell) will help write code that follows common standards.
The code is ready to be submitted as a pull request when the NewApiHandler implementation is cleanly checked into a separate git branch. MindsDB provides a pull request template with a very useful checklist. Closely following the pull request checklist significantly simplifies reviews.
Working on the GitHub handler, I narrowed the scope of the first pull request to include the GithubHandler class and the GithubIssuesTable class with the select method only. Pulling GitHub issues into MindsDB with a simple SELECT query adequately demonstrated the potential of my GitHub Handler implementation. The pull request was sized appropriately with 400 new lines of code that included my documented future plans for the GitHub Handler. I added a comment about my pull request to the original GitHub Integration issue, and I posted on the MindsDB Community Slack.
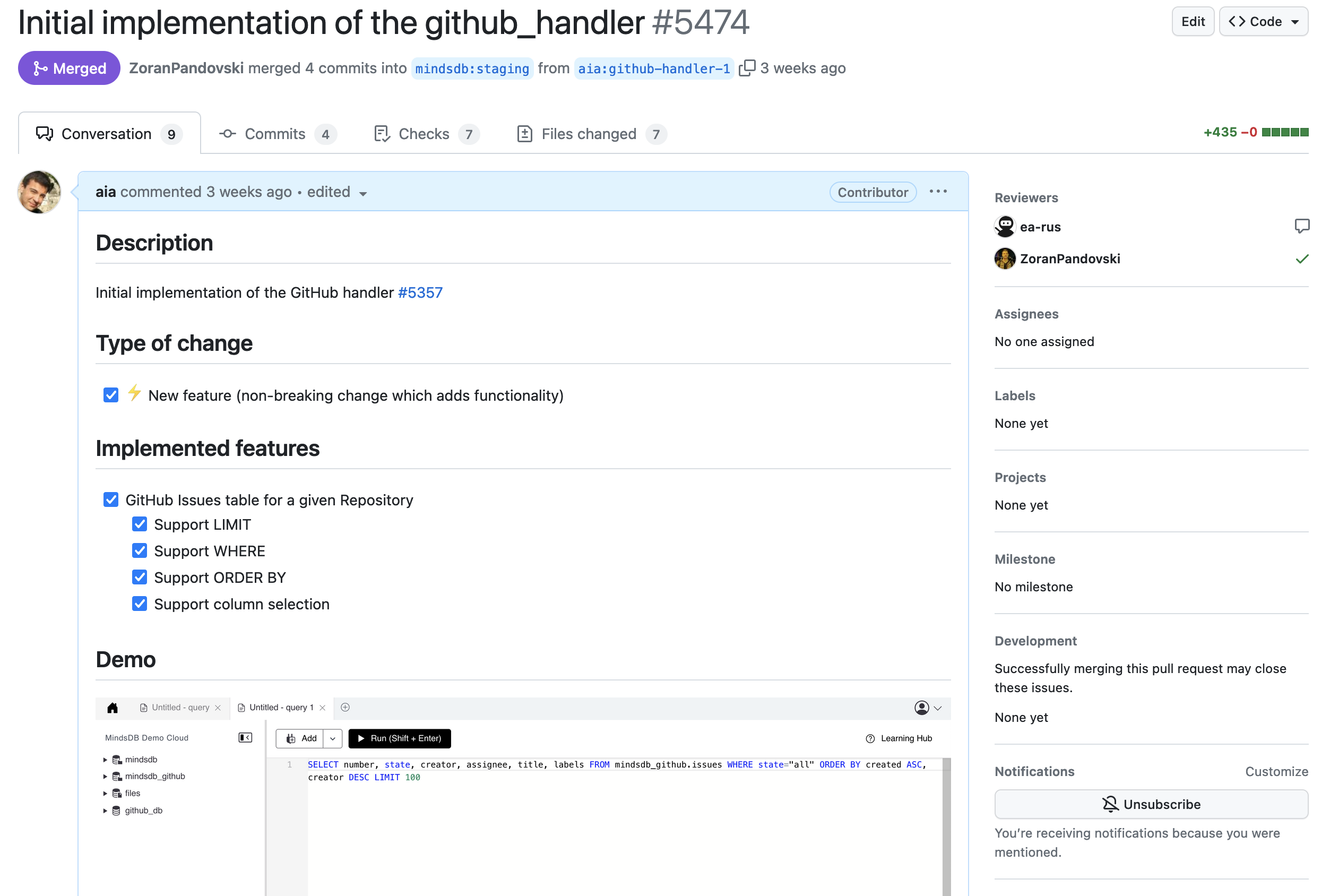
Pull requests are submitted when the authors are ready to receive feedback. Great developers actively seek feedback and take action. Feedback from pull request reviewers is one of the most important practices that continuously improve the quality of the codebase. On my first pull request for the GitHub handler, I received feedback about a mission connection check in my implementation. Focused on table design, I did not think about tracking and publishing the GitHub connection status. GitHub APIs, like many others, have request limits and throttling. Checking and logging the rate limit status is extremely helpful. The feedback I received helped me improve my code by adding useful functionality. After I made changes addressing the pull request feedback, my first pull request was successfully merged.
Checkpoint 4:
With good luck and perseverance, we have
- The first pull request for the new integration merged
Moving Forward One Iteration At A Time
The first pull request is just the beginning. Great projects are built one iteration at a time with carefully sized steps. Iterative development is one of the most effective software development techniques. The inexpensive nature of iterations in software development is one of the key reasons why software is eating the world. Persistent iterations can turn the most humble software beginning into an advanced product.
The implementation plan created earlier in the article should have enough ideas for the follow-up pull requests. In the next pull request for the GitHub handler, I published the insert method for the GithubIssuesTable class.
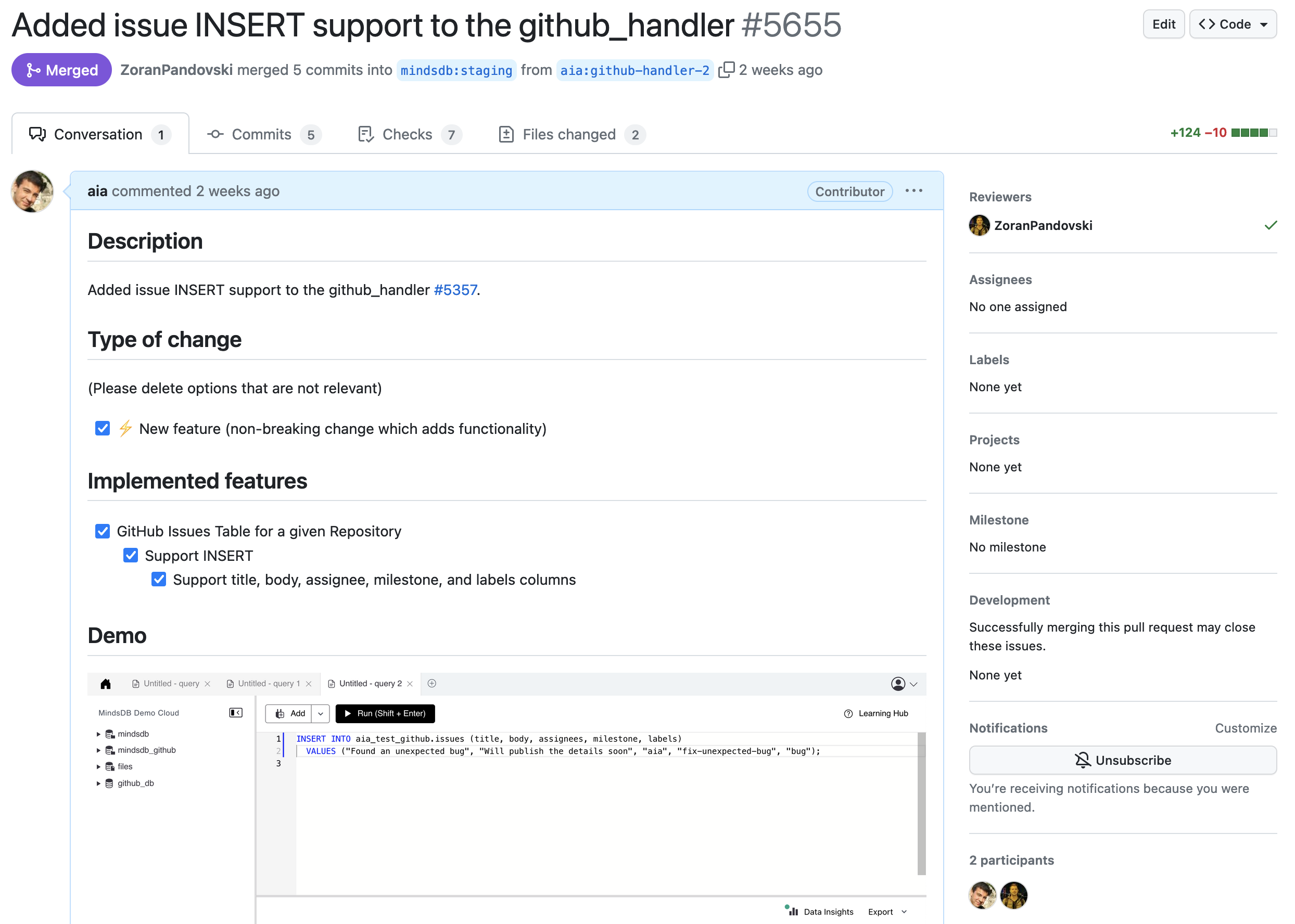
The review complexity for my second pull request decreased significantly. Small pull requests allow the author to maintain a laser focus on the target and continue to develop a deeper understanding of the feature. My third pull request implements GithubPullRequestsTable class and is currently under review.
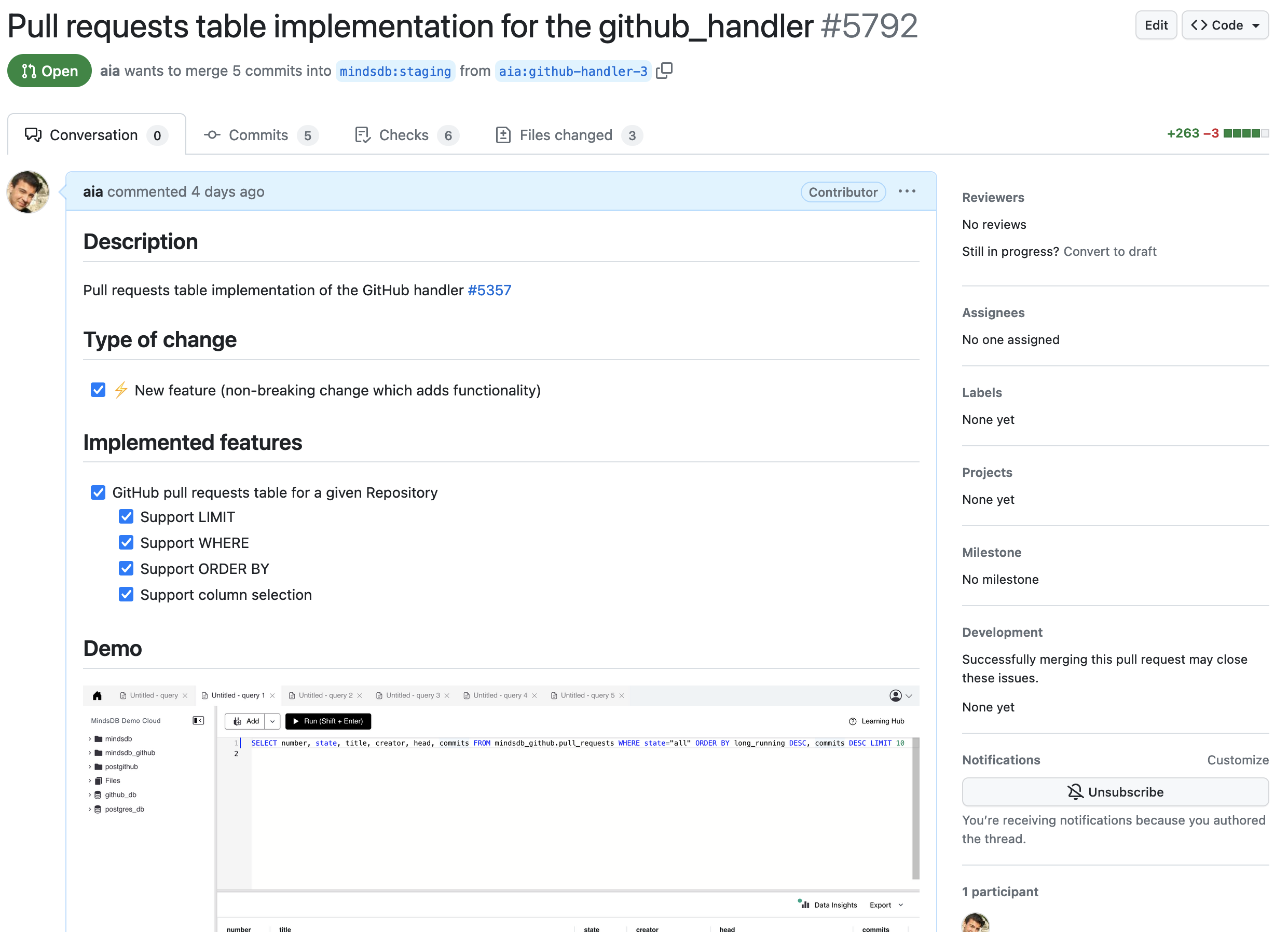
I am about half way through my implementation plan. My next steps are:
GitHub Commits Table for a given Repository
GitHub Releases Table for a given Repository
GitHub Contributors Table for a given Repository
GitHub Branches Table for a given Repository
Checkpoint 5:
- After multiple iterations, the new MindsDB integration is at the point where it provides powerful functionality.
Building a Product
Powerful products are created through powerful integrations. While feature implementation in code is a linear experience, the road from code to product does not follow a linear path. As someone who is still a humble student of product development, I can only share my thoughts about the product use of the GitHub handler.
I am currently working on implementing a semantic search of GitHub issues with MindsDB. The existing GitHub issue search is very rudimentary. Large open-source projects like MindsDB go through thousands of issues. When I open a new issue in a project with a huge issue history, I often wonder whether the topic was brought up before.
OpenAI offers powerful embeddings APIs that can be used to implement semantic search. In my product MVP, I'd like to load all issues from a project with the MindsDB GitHub handler and store them in a Postgres table. After the data load, I will use the OpenAI embeddings API to calculate vectors for each issue and store them in new columns. I will leverage the PgVector Postgres extension to enable SELECT from issues based on emeddings. When a new issue is created, a GitHub bot can post a comment linking similar past issues.
I am very excited about exploring OpenAI embeddings APIs with PgVector and MindsDB!